

Disk I/O(Input/Output, 디스크 입출력)는 디스크에서 데이터를 읽거나 쓰는 작업을 의미합니다.
즉, 디스크에서 데이터를 가져오거나 저장하는 모든 과정이 Disk I/O라고 할 수 있습니다.
1. Disk I/O의 기본 개념
컴퓨터에서 데이터를 읽고 쓰는 방식은 크게 메모리(RAM)와 디스크(SSD/HDD) 두 가지가 있습니다.
- 메모리(RAM)에서 읽기/쓰기
- 속도가 매우 빠름 (나노초(ns) 단위)
- 전원이 꺼지면 데이터가 사라짐(휘발성)
- 디스크(HDD/SSD)에서 읽기/쓰기 (Disk I/O)
- 속도가 느림 (마이크로초~밀리초 단위)
- 데이터를 영구적으로 저장 (비휘발성)
디스크는 메모리에 비해 속도가 훨씬 느리기 때문에, Disk I/O가 많아지면 성능이 저하됩니다.
즉, 데이터를 디스크에서 읽어오는 과정이 많아지면 성능이 떨어질 수 있다는 의미입니다.
2. Disk I/O가 중요한 이유
디스크는 CPU, 메모리보다 속도가 느리므로 Disk I/O가 많아지면 시스템 성능이 저하됩니다.
- Disk I/O가 많아질 때 발생하는 문제
- 쿼리 속도 저하 (데이터베이스가 디스크에서 데이터를 계속 읽어야 해서 느려짐)
- 애플리케이션 응답 속도 저하
- CPU 대기 시간이 증가 → 병목 현상 발생
3. Database와 Disk I/O
데이터베이스에서 Disk I/O를 줄이는 것이 매우 중요합니다.
Disk I/O가 많으면 쿼리 성능이 저하되므로, 이를 최적화하는 방법이 필요합니다.
- Disk I/O를 줄이는 방법
- 인덱스 활용 → 테이블 전체를 검색하는 **풀 테이블 스캔(Full Table Scan)**을 줄이면 Disk I/O 감소
- 쿼리 최적화 → SELECT * 대신 필요한 컬럼만 조회
- 캐싱(Cache) 활용 → 자주 조회하는 데이터를 메모리에 저장해 Disk I/O 최소화
- 메모리 증가 → 더 많은 데이터를 메모리에 올려서 디스크 접근을 줄임
- Partitioning(파티셔닝) → 큰 테이블을 분할하여 필요한 데이터만 빠르게 조회
4. Disk I/O 예제
X Disk I/O가 많은 경우 (풀 테이블 스캔)
SELECT * FROM users WHERE age > 30;- age 컬럼에 인덱스가 없으면 테이블 전체를 뒤져야 함 → Disk I/O 증가
- 데이터가 많아질수록 성능 저하 심각
O Disk I/O를 줄이는 경우 (인덱스 활용)
CREATE INDEX idx_users_age ON users(age);
SELECT * FROM users WHERE age > 30;- age 컬럼에 인덱스가 있어 필요한 데이터만 빠르게 조회
- 테이블 전체 조회를 방지하고 Disk I/O 최소화
데이터베이스 저장소, 디스크 Disk
데이터베이스에서 데이터를 저장하고 관리하는 장치로 디스크를 가장 많이 사용한다. 디스크는 메모리 공간이 넉넉한 반면에 속도가 느리다는 단점이 있다. 그래서 메모리에 임시로 데이터를 저장하여 빠르게 읽어올 수 있는 캐시를 사용하여 웹 서비스 성능을 향상시키기도 한다. 메모리에 접근할 때는 나노초(ns)단위로 처리할 수 있으나, 디스크에 접근할 때는 밀리초(ms)단위의 시간이 필요하다. 사람 입장에서는 ms가 빠를 수도 있겠지만 컴퓨터 입장에서는 상대적으로 굉장히 느린 속도이다.
디스크 I/O 부분이 성능에 가장 영향을 미치는 요소이다. 보통 디스크 I/O는 데이터베이스에 데이터를 기록하고 기록된 정보를 찾아 꺼내오는 것을 말한다. DBMS 입장에서 보면 디스크 I/O는 반드시 필요한 기능이면서도 처리 시간을 최대한 단축시켜야 하는 부분이기도 하다.
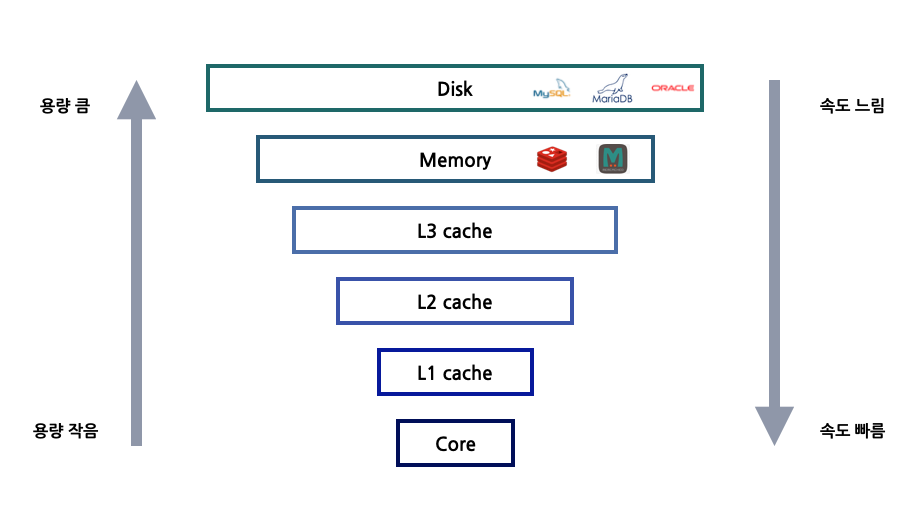
컴퓨터 메모리 계층 구조
어떻게 디스크 I/O 대기 시간을 줄일까?
메모리에 테이블의 데이터가 없으면 풀 스캔(Full Scan, 테이블의 모든 데이터를 읽어오는 것)할 때 시퀀셜 액세스가 발생한다. 시퀀셜(sequential) 액세스란? 'sequential'은 '순차, 순서를 따라서'라는 의미를 뜻한다. 그래서 시퀀셜 액세스는 시작점에서부터 마지막까지 중간 부분을 생략하지 않고 전부 액세스(읽기/쓰기)하는 것을 의미한다. 시퀄셜 액세스와 풀 스캔은 DB를 이해하기 위해 꼭 알아야 하는 중요한 개념이다.
인덱스 Index
이러한 디스크 I/O 성능 문제를 해결하고자 인덱스(index, 색인)이라는 개념이 나오게 되었다. 색인은 실생활에서도 쉽게 접해볼 수 있는 개념이다. 흔히 책에서 찾아볼 수 있는 색인은 키워드가 순서대로 나열되어 있으며, 해당 페이지도 함께 기재되어 있다. 그 페이지 번호를 이용해서 원하는 페이지를 빠르게 찾은 후 필요한 정보를 얻어낼 수 있다.
데이터베이스 인덱스도 마찬가지이다. 데이터베이스 인덱스에는 검색할 때 사용하는 키 값(SQL문의 WHERE절에 적는 조건의 값)과 그 키가 존재하는 있는 위치가 기록되어 있다.
- 데이터 = 책의 내용, 인덱스 = 책의 목차, 물리적 주소 = 책의 페이지 번호
인덱스 사용 예
가계부에서 5월 20일에 사용한 결제 내역을 정보를 모두 찾아보고 싶을 때 해당 요일에 기록된 장부를 펼쳐보면 된다. SQL문도 마찬가지로 WHERE절에 date = "20220520"에 기록된 가계부 내역을 찾고 싶다는 것을 작성하고 SELECT 절에 알고 싶은 항목을 적는다.
SELECT * FROM Pay WHERE date ='20220520';
인덱스를 사용해서 이 SQL문을 처리할 때는 우선 'date'가 기록되어 있는 인덱스를 조사한다. 그 결과 pointer(talbe 저장된 위치, rowid)를 알아낼 수 있고 그 주소를 토대로 데이터를 읽을 수 있다.
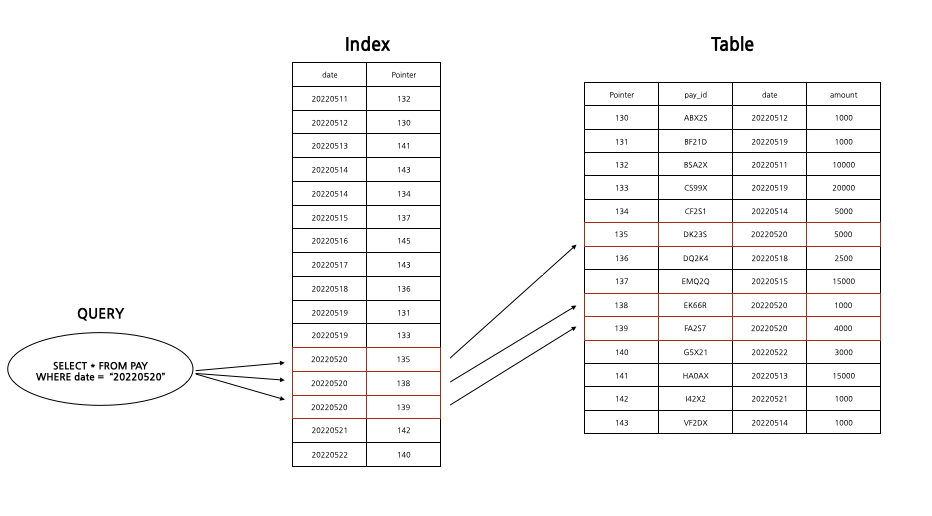
Index
장점
인덱스의 장점은 테이블 검색을 빠르게 진행하여 디스크 I/O 부분 성능을 향상시켜 준다는 점이다.
단점
단점으로는 인덱스를 관리하는 추가적인 작업과 그만한 공간이 필요하다. 그리고 update(수정/ 삭제)가 빈번하게 일어나는 컬럼에 인덱스를 사용하면 데이터의 인덱스를 제거하는 것이 아니라 '사용하지 않음'으로 처리하고 남겨두기 때문에 오히려 배보다 배꼽이 커질 수도 있다. 그리고 조회 범위(15~25% 이상)를 잘못 설정하는 경우 오히려 성능을 저하시키기도 한다.
5. 정리
Disk I/O란? 디스크에서 데이터를 읽거나 쓰는 모든 작업을 말한다.
왜 중요한가? 속도가 느려서 많아지면 쿼리 성능 저하된다.
최적화 방법: 인덱스 활용, 캐싱, 메모리 증설, 파티셔닝 등을 활용한다.
DB 성능 튜닝의 핵심은 Disk I/O를 줄이는 것이다.
참고 :
https://f-lab.kr/insight/database-index-disk-io-20250217
https://gist.github.com/taekwon-dev/3ff3f4ae55926aba8f95fbce0d65dd43
'DB' 카테고리의 다른 글
| MySQL 8.0 'Access denied' 오류 해결법 — 인증 방식 변경 [우분투,mySQL8.0] (0) | 2025.04.02 |
|---|---|
| [MySQL] EXPLAIN 실행 계획 항목 정리 (0) | 2025.03.21 |
| [DB MySQL] 옵티마이저(Optimizer)란? INDEX EXPLAIN 실행 (0) | 2025.03.20 |
| 복합 인덱스(Composite Index)와 B-Tree 원리 분석 - 1억 개 이상의 데이터 빠르게 조회하기 (0) | 2025.03.18 |
| [ Database ] ER 다이어그램 / ERD 기호 및 표기법 (1) | 2023.03.14 |