
목차
1. 카프카(kafka)란 무엇인가?
2. 초보 개발자가 가장 많이 헷갈리는 질문
3. 컨슈머와 리스너의 진짜 역할
4. 실제 동작 구조를 하나의 흐름으로 정리해보면
5. 헷갈리는 개념들을 한 번 더 정리하면
6. 카프카를 처음 도입하는 팀이라면
카프카(Kafka) 기본 개념 정리 – 컨슈머와 리스너는 어떻게 다를까?
최근에 회사 프로젝트에서 카프카(Kafka)를 도입하면서 가장 많이 부딪힌 부분이 바로 “컨슈머(Consumer)와 리스너(Listener)가 뭐가 다른가?”였다.
설계 문서를 보면 둘 다 메시지를 받고 처리하는 것처럼 보이는데, 실제로는 서로 완전히 다른 역할을 담당한다.
초보 개발자들이 가장 헷갈려 하는 부분이기도 해서, 처음 접하는 사람 기준으로 정리해본다.
1. 카프카(Kafka)란 무엇인가?

카프카는 여러 시스템 사이에서 데이터를 빠르고 안정적으로 전달하기 위한 메시지 스트리밍 플랫폼이다. 쉽게 말하면, 서비스들 사이에서 주고받는 데이터를 한 곳에 모아두고, 필요한 서비스가 가져다 쓰는 구조다.
HTTP API처럼 “서버 ↔ 서버”가 실시간으로 직접 통신하는 방식과 달리, 카프카는 중간 저장소(토픽) 에 데이터를 쌓아두고 다른 서비스가 이를 언제든 읽어갈 수 있게 만든다.
이 방식은 서비스 간 결합도를 낮추고, 장애나 지연이 생겨도 전체 시스템을 보호해주는 장점이 있다.
카프카의 핵심 구성 요소는 다음과 같다.
- 토픽(Topic) : 메시지를 종류별로 모아놓는 저장소
- 메시지(Message) : 실제 데이터
- 프로듀서(Producer) : 메시지를 카프카에 보내는 쪽
- 컨슈머(Consumer) : 메시지를 카프카에서 가져오는 쪽
- 브로커(Broker) : 카프카 서버
- 파티션(Partition) : 토픽을 병렬 처리하기 위해 쪼개놓은 단위
- 오프셋(Offset) : 메시지의 번호(위치)
여기까지는 공식 문서에서도 흔히 나오는 설명이지만, 문제는 이 다음 단계에서 많이 헷갈린다.
2. 초보 개발자가 가장 많이 헷갈리는 질문
카프카에서 메시지가 들어오면, 스프링 애플리케이션에 있는 리스너가 자동으로 실행된다.
이 때문에 흔히 이런 흐름을 상상하게 된다.
- 서비스 A가 메시지를 Kafka에 보냄
- Kafka가 토픽을 확인한 뒤
- 스프링 서비스의 리스너에게 메시지를 “전달”해줌
하지만 실제 동작 방식은 이와 정반대다.
카프카는 메시지를 직접 보내주지 않는다.
3. 컨슈머와 리스너의 진짜 역할
3-1. 컨슈머(Consumer)란?
컨슈머는 카프카에서 메시지를 직접 가져오는 주체다.
중요한 사실은, Kafka는 메시지를 애플리케이션에게 “푸시”하지 않는다.
컨슈머가 지속적으로 “폴링(polling)”하여 메시지를 가져간다.
즉, “새 메시지 있나요?” 하고 Kafka에 계속 물어보는 역할을 담당하는 것이 컨슈머다.
이를 이해하는 순간 전체 구조가 확실히 잡힌다.
3-2. 리스너(Listener)란?
리스너는 스프링에서 제공하는 일종의 콜백 함수다.
컨슈머가 Kafka에서 메시지를 가져오면, 그 메시지를 전달받아서 비즈니스 로직을 처리하는 메소드가 바로 리스너다.
예를 들어 아래 코드처럼:
@KafkaListener(topics = "order-created")
public void handleOrder(String message) {
// 메시지가 들어왔을 때 실행되는 로직
}이 메소드 자체가 “리스너”다.
이 리스너는 메시지를 직접 읽지 않는다.
메시지를 읽는 행위는 컨슈머가 하고, 읽은 메시지를 리스너에게 전달해주는 역할을 스프링의 리스너 컨테이너가 대신한다.
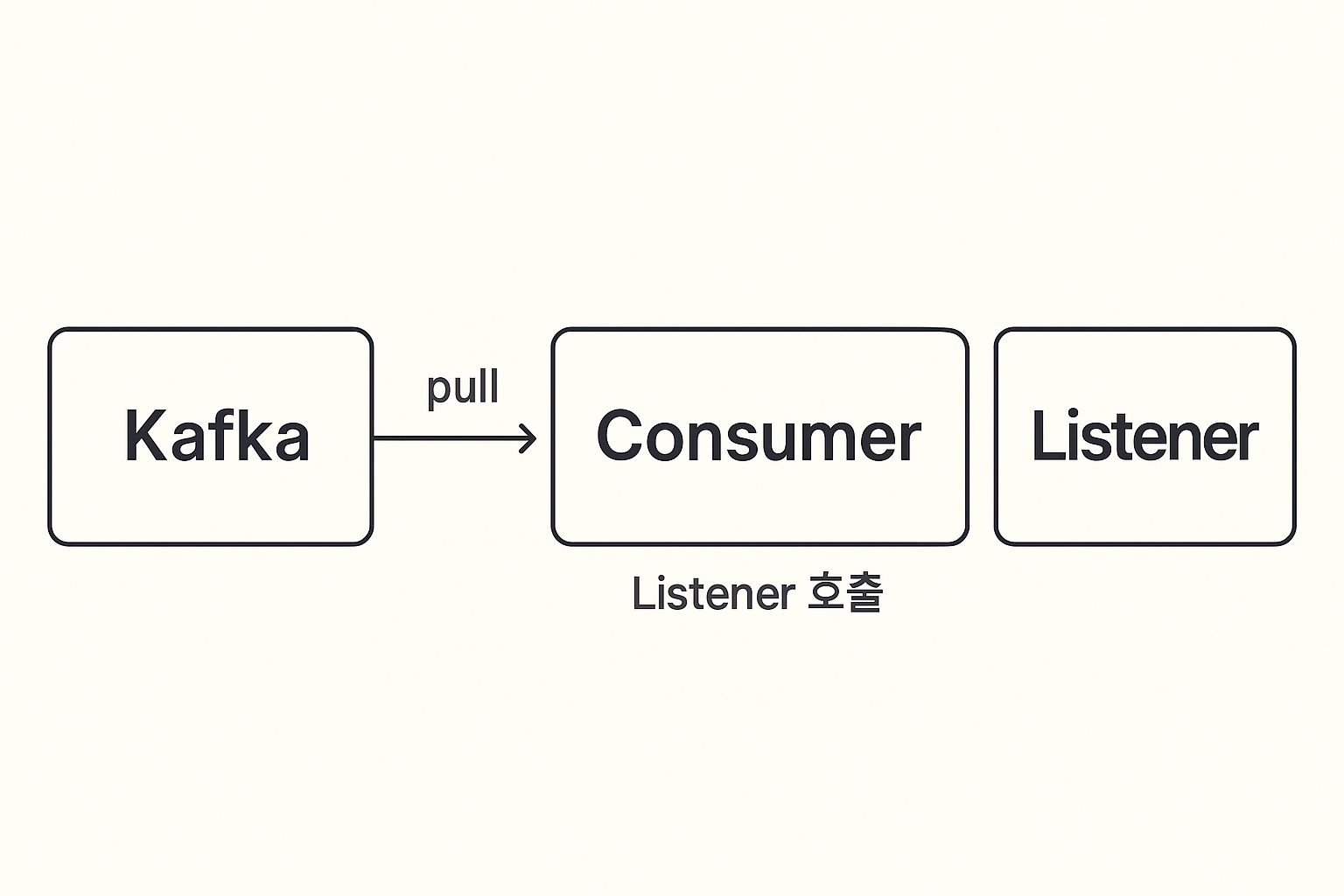
4. 실제 동작 구조를 하나의 흐름으로 정리해보면
카프카를 처음 배울 때 가장 중요한 이해 포인트는 이 그림 하나로 정리된다.
Kafka ← (pull) ← Consumer → Listener 호출흐름을 순서대로 보면 다음과 같다.
- Producer가 Kafka의 특정 Topic에 메시지를 저장한다.
- Spring 애플리케이션 내부의 Consumer가 Kafka에게 지속적으로 폴링한다.
- Kafka에서 새 메시지가 발견되면 Consumer가 해당 메시지를 가져온다.
- Consumer가 가져온 메시지를 Spring이 Listener 메소드에 전달한다.
- Listener가 메시지를 기반으로 비즈니스 로직을 실행한다.
즉, 핵심은 카프카는 메시지를 직접 보내주지 않는다는 점이다.
메시지를 읽는 주체는 항상 컨슈머,
메시지를 처리하는 주체는 리스너다.
둘은 역할이 명확히 분리되어 있다.
5. 헷갈리는 개념들을 한 번 더 정리하면
● 카프카는 API 서버가 아니다
카프카에 “요청”을 보내는 것이 아니라,
Producer가 메시지를 보내고 Consumer가 가져가는 구조다.
● 리스너는 메시지를 읽지 않는다
리스너는 오직 “메시지가 전달되었을 때 실행되는 메소드”일 뿐이다.
실제 읽기(read)는 Consumer가 담당한다.
● 카프카는 push가 아니라 pull 방식이다
카프카가 Spring에 “보내주는 것처럼” 보이지만,
실제로는 스프링 내부의 Consumer가 카프카에서 계속 메시지를 가져오고 있을 뿐이다.
● Listener는 Spring이 만든 편의 기능
원래 Kafka에는 Listener라는 개념이 없다.
Spring Kafka가 Consumer에서 읽어온 메시지를 자동으로 메소드에 연결해주기 위해 만든 사용성 개선 기능이다.
6. 카프카를 처음 도입하는 팀이라면
실제 업무에서 카프카를 다루다 보면 Producer보다 Consumer가 훨씬 중요하다는 걸 느끼게 된다.
메시지 중복 처리, 오프셋 관리, 장애 복구 전략, 컨슈머 그룹 운영 등은 모두 Consumer 구조를 정확히 이해하는 것에서 출발한다.
특히 스프링을 사용한다면 “컨슈머가 메시지를 가져온 뒤 리스너에게 넘겨준다”는 구조를 명확히 이해하는 것이 전체 로직을 안정적으로 유지하는 데 큰 도움이 된다.
마무리
처음에는 나 역시 카프카가 메시지를 스프링 애플리케이션으로 직접 “보내주는” 방식이라고 오해했다.
하지만 내부 구조를 정확히 알고 나면, 컨슈머와 리스너가 왜 분리되어 있고 어떤 역할을 맡고 있는지 훨씬 명확하게 정리된다.
이 글이 카프카를 처음 접하는 개발자들에게 도움이 되길 바라며,
향후에는 실제 예제 코드와 함께 컨슈머 그룹 운영 방식, 파티션 전략, 재처리 로직 등 좀 더 깊은 내용을 다뤄볼 계획이다.
'Spring' 카테고리의 다른 글
| [Spring Boot] JUnit5 + Mockito 단위 테스트 기초 정리 (0) | 2025.11.27 |
|---|---|
| [DDD] Value Object의 동일성과 동등성 완벽 이해하기 Value Object의 동일성과 동등성 완벽 이해하기 (0) | 2025.10.22 |
| [DDD] 자바에서의 참조 공유와 (Value Object, Entity) 정리 (0) | 2025.10.17 |
| Spring Security 기반 CSRF 공격 실습 및 방어 방법 정리 (1) | 2025.05.04 |
| [QueryDSL 오류]Springboot 3.0이상에서 QueryDslConfig Cannot resolve constructor 'JPAQueryFactory(EntityManager)' (0) | 2025.02.21 |